Situation
In the weeks after the Alexa+ announcement, Alexa leadership felt that we were not progressing quickly enough towards a release-quality conversational experience. In particular, they identified a number of anecdotal experiences where they felt that Alexa+ seemed dull and robotic. As the Conversational Excellence product/design/engineering/science team, we were asked to improve these experiences as quickly as possible.
Until that point, we had focused on improvements through prompt engineering, but had found that in certain areas, our model was “stubborn” and resistant to system instructions that tried to override strong leanings in its training. We needed a different approach.
Task
We spun up a new initiative that focused on addressing these anecdotal issues through a combination of prompt engineering and model fine tuning. We knew that in order to improve performance, we would need to turn those anecdotal bad experiences into identifiable patterns that could be evaluated systematically. Once we had that, we could create A/B response datasets that would demonstrate both undesirable and desirable behaviors; those datasets could then be used both for model fine-tuning and for model evaluation.
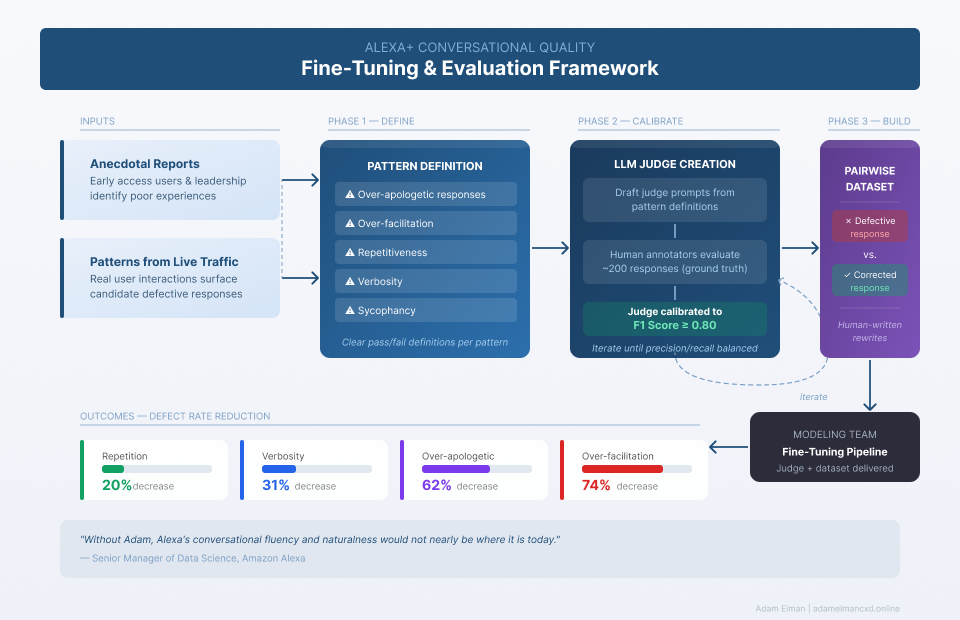
The patterns we identified included overly apologetic responses; over-facilitation (asking too many questions); repetitiveness (e.g., repeating proper names or other phrases in an unnatural way within and across conversational turns); verbosity, and overly agreeable/sycophantic responses.
Action
As the lead conversation designer and a key driver for this initiative, I worked closely with the product, science, and engineering teams, as well as a group of ~10 conversation design contractors that my manager and I hired, to establish a workflow for these datasets. We quickly identified that we needed to create measurable metrics for each pattern we wanted to influence, and then identified two primary stages for each metric.
- We would need judges – an evaluation script, generally using LLMs, that could look at a set of sample responses and predict to a fair degree of accuracy whether a human evaluator would consider the response “good” or “bad” for the metric in question.
- We would need training data – a set of prompts and responses that demonstrated both a “violation” of the metric (ideally, one generated by the model itself), and a “non-violation” (generally rewritten by a human annotator).
For each metric, I began by carefully analyzing patterns in the anecdotal reports provided by early access users, including our leadership, and creating a clear definition of the issue that outlined what kinds of responses would be considered acceptable vs not. I then worked with our data science team to create draft LLM judge prompts that modeled these definitions. We then ran the judge prompts over actual beta usage traffic to create candidate sets of “good” and “bad” responses (generally around ~200).
Next, I created a spreadsheet with the candidate dataset and created a set of task instructions for the CxD contractors to evaluate the responses to give us a “ground truth.” To avoid bias, the contractors did not see the initial LLM judge responses. I assigned the work to the contractors, then reviewed the evaluations and updated them where necessary, providing extensive feedback to the contractors to improve their efforts. Once I was comfortable with the results I provided them to the data scientists, who iterated the prompt to better match ground truth. I adjudicated any conflicts and ambiguities, adjusting the definition where necessary to provide more clarity, until the LLM judge prompt was able to reach an F1 score (the mean of precision vs recall) of 0.8, demonstrating high predictive capability.
Once we had a well-calibrated judge, the data scientists ran it over a larger set of traffic to identify a set of “defective” responses, which I packaged and assigned to the contractors to rewrite. I then reviewed these rewrites carefully, made adjustments to them, provided feedback to the contractors, and returned them to the data scientists to evaluate. The rewritten responses sometimes still were judged defective; where this happened, I reviewed them and decided whether to ask the contractor team for further rewrites, exclude the response from the dataset, or in some cases adjust the judge itself.
Ultimately, for each pattern we delivered to the modeling team some combination of a calibrated judge and a pairwise dataset with defective and non-defective responses that met their requirements for model training.
Results
Over the course of several model releases, we were able to make significant reductions in defect rates across live traffic. We saw a 20% decrease in repetition defect rate; a 31% decrease for verbosity, a 62% decrease for over-apologetic responses, and a 74% decrease in defect rate for over-facilitation.
One senior manager of data science said of this effort, “Without Adam, Alexa’s conversational fluency and naturalness would not nearly be where it is today.”